





Os elementos estruturais do ambiente integrado constituído pelos produtos da família OpenBASE são agrupados conforme as seguintes categorias:
A seguir apresentamos com maiores detalhes os componentes acima referenciados.
Um Banco de Dados OpenBASE consiste de um Dicionário de Dados e de um ou mais arquivos de dados com seus respectivos índices.
O Dicionário de Dados é um arquivo em disco que contém a estrutura de um Banco de Dados e as informações necessárias para o gerenciamento do Banco de Dados.
É através do Dicionário que as rotinas de manipulação de dados acessam o Banco de Dados e reconhecem as estruturas de dados de cada arquivo.
Os arquivos de dados armazenam os registros de dados, segundo as especificações contidas no Dicionário de Dados. Arquivos de dados no OpenBASE são categorizados em função dos conjuntos de objetos básicos do MER original, ou seja, representam os conjuntos de Entidades e Relacionamentos. Assim sendo, o OpenBASE oferece dois tipos básicos de arquivos de dados:
Em condições especiais um Arquivo Entidade pode assumir a qualidade de Arquivo Tabela e um Arquivo Relacionamento a qualidade de Arquivo Consulta. O uso dos arquivos Tabela e Consulta, ocorre quando existe a necessidade de se definir em um Banco de Dados, arquivos que já foram definidos em outros Banco de Dados, ou seja, implementar interseções de Banco de Dados sem que haja redundância.
Além dos arquivos de dados, o OpenBASE implementa internamente arquivos de índices. Os arquivos de índices são gerados quando são atribuídas determinadas características especiais aos itens de dados, como:
No OpenBASE uma chave secundária (estrangeira ou alternativa) pode ser chave única. Não devemos confundir esta restrição de unicidade com as características da Chave Primária que é chave única em função de sua própria natureza (Atributo Determinante). Itens redefinidos ou virtuais podem constituir-se também em chaves. O OpenBASE implementa vários tipos de índices em função da unicidade ou multiplicidade das chaves:
Os índices simples são construídos quando ocorrem chaves primárias (únicas por definição) ou chaves secundárias únicas, onde as chaves mantém uma relação 1:1 com os registros no arquivo de dados.
Os índices estruturados são determinados pela ocorrência de chaves secundárias não únicas, onde as chaves mantém uma relação 1:N com os registros no arquivo de dados.
Para cada chave secundária não unívoca é criada, nos registros do arquivo de dados, uma área adicional denominada cabeçalho correspondente a entradas numa lista duplamente encadeada que gerencia os registros que contém as mesmas chaves.
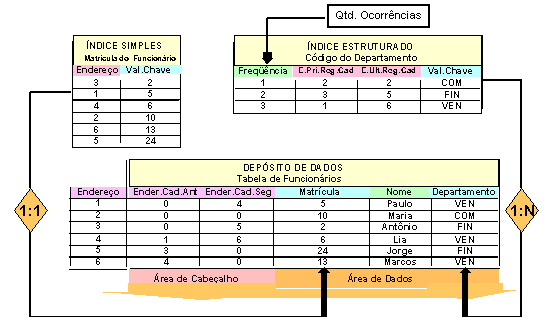
.
Este componente de Bancos de Dados OpenBASE é opcional. No Esquema de um Banco de Dados pode ser definido o recurso de recuperação através da opção ARQRECUP cuja finalidade é armazenar no arquivo de recuperação as imagens originais dos dados das uma transações antes de serem modificados.
Este recurso permite que uma ou mais transações possam ser desfeitas através dos procedimentos rollback ou undo). A quantidade de Arquivos de Recuperação deste tipo varia em função da estratégia de bloqueio adotada.
Este componente de Bancos de Dados OpenBASE é opcional. No Esquema de um Banco de Dados pode ser definida a utilização de um recurso de recuperação através das opção DIARIO ou DIAREC.
Especificando a opção DIARIO, o OpenBASE armazena no arquivo diário (journal) as informações lógicas dos dados depois de serem modificados permitindo, assim, que uma ou mais transações sejam refeitas a qualquer momento, a partir de uma determinada hora ou a partir de uma determinada transação OpenBASE. Especificando a opção DIAREC, o OpenBASE armazena no arquivo diário (journal) as informações lógicas dos dados antes de serem modificados e depois de serem modificados permitindo, assim, que uma ou mais transações sejam desfeitas ou refeitas a qualquer momento, a partir de uma determinada hora ou a partir de uma determinada transação OpenBASE.
As opções DIARIO e DIAREC implicam na utilização automática da opção ARQRECUP. O arquivo diário pode ser único para todos os Bancos de Dados que utilizem estas opções ou não, dependendo das especificações no esquema. O arquivo diário é criado pelo programa BDSGBD, responsável por alguns controles do ambiente operacional dos Bancos de Dados OpenBASE.
Após a compilação do esquema do Banco de Dados, são gerados os seguintes arquivos com o mesmo nome do Dicionário de Dados, mas com diferente extensão:
<dicion> Nome do dicionário de Dados.
<dicion>.B Arquivo criado, quando se utiliza bloqueio de banco.
<dicion>.C Indica que estão sendo usados domínios para arquivos transposto.
<dicion>.G Quando se utilizam bancos de dados distribuídos, indica o arquivo gerado na máquina cliente que informa o percurso local do dicionário de dados no servidor.
<dicion>.H Quando se utilizam bancos de dados distribuídos, este arquivo é gerado em cada máquina que compõe o banco de dados distribuído:
<dicion>.L Quando se utilizam bancos de dados distribuídos, este arquivo armazena a imagem anterior das transações não completadas nos arquivos que compõem o banco de dados distribuído.
<dicion>.P Arquivo criado, quando o percurso e nome do dicionário, arquivos e itens, possuírem tamanho maior que 56 posições.
<dicion>.R Arquivo de recuperação, gerado quando foi especificado o parâmetro <ARQRECUP> na declaração do esquema. O OpenBASE gera sempre este arquivo, anão ser que seja especificado <NAOARQRECUP>.
<dicion>.S Arquivo que contém as informações de data-hora relativas aos arquivos replicados.
<dicion>.T Indica que está se utilizando espelhamento de arquivos de dados.
<dicion>.Z Arquivo com as informações necessárias para refazer as transações. <ARQREFAZ> especificado na declaração de um Banco de Dados OpenBASE.
O processo de implementação de Bancos de Dados OpenBASE inclui duas etapas:
A definição de Bancos de Dados OpenBASE inclui a elaboração de um esquema, que é a tradução do projeto lógico (MER) para a linguagem de definição de Dados do OpenBASE. O esquema descreve detalhadamente todas as informações necessárias que constituem o Dicionário de Dados do Banco de Dados, tais como:
O arquivo texto que contém o esquema é submetido ao programa "DEFINE" para processá-lo, sendo criado, efetivamente, um Banco de Dados OpenBASE com os seguintes componentes básicos:
O OpenBASE possui sua própria Linguagem de Definição de Dados (LDD) que permite construir o esquema conceitual de cada Banco de Dados, descrevendo sua estrutura completa, concentrando-se, especificamente, na arquitetura e descrição de entidades, atributos, relacionamentos, procedimentos de integridade e recuperação, estratégias de bloqueio, níveis de acesso e regras de utilização.
Existem diferentes terminologias associadas aos conceitos básicos do modelo relacional, dependendo do contexto. A Linguagem de Definição de Dados do OpenBASE, baseada no modelo conceitual Entidades - Relacionamentos (E-R), utiliza a terminologia comum de processamento de dados, ou seja, arquivo, registro e item (ou campo). O modelo relacional formal apresenta a terminologia relação, tupla e atributo ou, ainda, tabela, linha e coluna (no contexto do SQL e modelo relacional informal).
O esquema conceitual de um Banco de Dados OpenBASE reside num arquivo texto, que pode ser construído ou modificado através de um editor de texto ou utilizando os recursos gráficos e visuais do OpenBASE tais como OpenIDE, OpenDBA e Visual OPUS.
Um dos componentes da Linguagem de Definição de Dados, denominado DEFINE, compila o esquema, processa seus componentes de acordo com a sintaxe LDD do OpenBASE e constrói ou modifica os objetos do Banco de Dados, tais como dicionário de dados, tabelas de controle, arquivos de dados e arquivos de índice. Depois de concluída a compilação do esquema e a definição dos Bancos de Dados, os usuários podem efetuar as tarefas básicas de incluir, selecionar, alterar e suprimir objetos. Vejamos algumas características importantes em relação ao esquema:
Quando o processamento do esquema é completado com êxito, o DEFINE imprime um sumário contendo as seguintes informações: nome e tipos dos arquivos, quantidade de itens por arquivo, tamanho dos registros, tamanho dos cabeçalhos, numero de ligações entre as entidades, quantidade de chaves por arquivo, ... etc ...
Neste tópico apresentamos uma referência da Linguagem de Definição de Banco de Dados do OpenBASE comentando, passo a passo, sua sintaxe e mostrando alguns exemplos.
[<< <comentário> >>]
[$CONTROLE <opção>, ... , <opção>]
BANCO [<percurso>] <nome_bd> <código_de_seguranca>...
[{ARQRECUP / DIARIO / DIAREC}]...
[{BLOQARQ / BLOQCHA / BLOQPAG / BLOQREG}]...
[ESQUEMA=[<percurso_bd_origem>]<nome_bd_origem>...]
<código_de_seguranca_bd_origem>...
[<palavra_de_nível_bd_origem>] ]
[NIVEIS: <numero_nivel> <palavra_nivel>
<numero_nivel> <palavra_nivel>]
[RELACOES:]
NOME: [<percurso>] <nome_arquivo> <tipo_arquivo>...
[ESQUEMA = [<percurso_bd_origem>] <nome_bd_origem>...
<codigo_de_seguranca_bd_origem>...
[<palavra_de_nivel_bd_origem>] ]
[REGISTRO:]
<nome_item> [{[<rep>] / (<ligações>) / (<caminho>)/(0)}]...
<tipo>:<tamanho>[,<num_decimais>] ... | |
[(<num_nivel_ler>,<num_nivel_grav>)] ...
[{POS <nome_item_rd>[+ <deslocamento>] /...
VIRTUAL (<nome_item_part>, ..., <nome_item_part>)}] ...
[UNICA]
...
...
Dentro do esquema, podem ser incluídos comentários, podendo estar em qualquer lugar e ocupar várias linhas confirme a seguinte Sintaxe
[ << <comentário> >> ]
Onde: "<<" marca o inicio de um comentário e ">>" marca o fim de um comentário
Exemplos:
<< Isto e um comentário: primeira linha de um comentário de várias linhas >>
<< Isto e um comentário: segunda linha de um comentário de várias linhas >>
O comando $CONTROLE do Esquema é opcional, podendo ser usado pelo projetista do Banco de Dados para especificar opções de controle válidas para todo o processamento do Esquema fonte pelo programa DEFINE. O comando $CONTROLE deve ser especificado no início do fonte do Esquema (primeiro registro do Esquema).
Exemplo:
$CONTROLE ARQUIVOS=200, TABELA, ERROS=10, ITENS=500
Consulte o manual de referência "DEFINE" e as atualizações apresentadas nos BITs (Boletins Informativos Técnicos) para obter as informações detalhadas sobre a sintaxe e utilização do comando $CONTROLE e suas opções.
As opções especificadas poderão ter validade para todos os componentes de um Banco de Dados, desde que declaradas imediatamente após o comando $CONTROLE. Caso você deseje que as opções especificadas se apliquem apenas a determinados arquivos, basta que as mesmas sejam declaradas nos arquivos onde se deseja que as opções atuem. Vale lembrar que só faz sentido usar as opções de controle nos arquivos apenas para desligar opções ligadas no comando $CONTROLE.
Exemplos:
<<banco "a" definido em a.e>>
BANCO a 1 ARQRECUP
NOME: ae e
a (0) u03
b u05
<<banco "b" definido em b.e>>
$CONTROLE LIGAT, SEMINTEGR
BANCO b 1 arqrecup
NOME: be e
bc (0) u05
ba (ae) u03
Observação:
A opção de controle $SEMINTEGR do exemplo acima somente deve ser utilizada quando o usuário tiver certeza do que está fazendo. Utilizada de forma indevida, esta opção poderá acarretar sérios problemas de INTEGRIDADE no BANCO DE DADOS. Por exemplo, nas declarações do exemplo acima, um registro do arquivo "ae" poderá ser excluído no banco "a" mesmo havendo registros no arquivo "be" do banco "b" ligados a "ae", o que viola as regras básicas de integridade referencial no banco "b".
A declaração do Banco de Dados e feita através de um conjunto de comandos especificados, de forma ordenada, dentro do esquema conforma a seguinte Sintaxe
BANCO [<percurso>] <nome_bd> <cod_seg> ...
[{ARQRECUP / DIARIO / DIAREC / AUTOREC}] ...
[{BLOQARQ / BLOQCHA / BLOQPAG / BLOQREG}] ...
[ESQUEMA = [<percurso_orig>]<nome_orig> ...
<seg_origem> ...
[<nivel_origem>]]
[DISTRIB = [<servidor>]
A seguir descrevemos os comandos utilizados na declaração de um Banco de Dados OpenBASE assim como as suas respectivas opções. Veja o manual específico do sistema DEFINE para maiores detalhes.
|
Comandos |
Explicação |
|
BANCO |
Marca o início da declaração de um Dicionário de Dados OpenBASE |
|
<percurso> |
Indica o diretório completo onde será criado o Dicionário de Dados, sendo o valor default /usr/tsgbd/tsdic). No ambiente Windows o nome completo do percurso inclui a letra do Drive, que deve preceder o nome do diretório (ou pasta) onde reside (ou vai residir) o banco de dados OpenBASE. Caso não seja especificada a letra do Drive, serão aplicadas as seguintes regras:
Se um banco for migrado de Drive deve ser executado o comando define para inserir a informação do novo Drive no dicionário |
|
<nome_bd> |
especifica o nome do Dicionário de Dados: consiste de uma cadeia com até 12 caracteres, com as seguintes restrições:
|
|
<cod_Seg> |
especifica o código de segurança do Banco de Dados que consiste de um número inteiro entre 1 e 4.294.836.225 (inclusive). Este número é o escolhido pelo projetista do Banco de Dados como uma senha |
|
ARQRECUP |
Determina que seja criado um ou mais arquivos, destinados a armazenar os dados das transações antes deles serem modificados, permitindo assim que uma ou mais transações não completadas possam ser desfeitas a qualquer momento (rollback / undo) |
|
DIÁRIO |
Determina que seja utilizado o arquivo DIÁRIO para armazenar todos os dados das transações depois deles serem modificados, permitindo assim que uma ou mais transações completadas possam ser desfeitas ou refeitas, a qualquer momento, a partir de uma determinada data/hora ou a partir de uma determinada transação identificada pelo seu numero. Esta opção implica na utilização automática da opção ARQRECUP |
|
DIAREC |
Determina que seja utilizado o arquivo DIÁRIO (criado pelo programa BDSGBD) para armazenar todos os dados das transações antes deles serem modificados e depois deles serem modificados. |
|
AUTOREC |
A opção AUTOREC indica que ao ser aberto um banco, se o arquivo de recuperação contiver uma transação não completada, a recuperação será feita automaticamente sem solicitar a execução do utilitário BDRECU, desde que não exista nenhum outro processo ativo utilizando o banco e que o bloqueio seja do tipo banco |
|
BLOQARQ |
Determina, para todos os processos de atualização do Banco de Dados que a estratégia de bloqueio será baseada em bloqueio de Arquivos |
|
BLOQCHA |
Determina para todos os processos de atualização do Banco de Dados que a estratégia de bloqueio será baseada em bloqueio de chaves |
|
BLOQPAG |
Estabelece para todos os processos de atualização do Banco de Dados que a estratégia de bloqueio será baseada em bloqueio de páginas |
|
BLOQREG |
Determina para todos os processos de atualização do Banco de Dados que a estratégia de bloqueio será baseada em bloqueio de registros |
|
ESQUEMA = |
Indica que Dicionário de Dados referenciado em <nome.bd> conterá a estrutura de um subesquema, ou seja, a estrutura parcial de um Banco de Dados já existente. Esta cláusula determina que na compilação do subesquema, seja aberto o Banco de Dados que dará origem ao subesquema (BDO), com a finalidade de consistir as estruturas definidas em ambos. Assim sendo:
No caso de subesquema não é necessário declarar as cláusulas de controle (ARQRECUP, DIÁRIO, BLOQARQ / BLOQCHA / BLOQPAG / BLOQREG), em função de todos os controle estarem subordinados ao Banco de Dados ao qual o Subesquema se referencia |
|
<percurso_orig> |
Percurso onde se encontra o Dicionário de Dados do Banco de Dados que será referenciado no Subesquema |
|
<nome_orig> |
Nome do Dicionário de Dados do Banco de Dados que será referenciado no Subesquema |
|
<seg_origem> |
Código de segurança do Banco de Dados que será referenciado no Subesquema |
|
<nivel_origem> |
Palavra de nível do Banco de Dados que será referenciado no Subesquema |
|
DISTRIB= |
A opção DISTRIB indica que o banco de dados é distribuído. O nome do Host onde residem o Banco de Dados e seu servidor mestre está especificado pelo operando <servidor> |
Exemplos:
BANCO nota_fiscl 33 AQRRECUP DIÁRIO BLOQCHA
BANCO /usr/apl/bds/folha_pg 33 ESQUEMA=bd_rh 21 gerent
banco teste 1
Em caso de Bancos Distribuídos:
banco abc 1 distrib=TS1
nome: arq1 e servidor=TS2
c1(1) u03
nome: arq2 r servidor=TS3
c2(arq1) u03
Em um Banco de Dados OpenBASE são estabelecidos níveis de acesso às informações para os diversos perfis de usuários. Os níveis de acesso especificados podem ser proporcionais aos perfis funcionais dos usuários que manipulam as informações dentro de uma organização qualquer.
Sintaxe
NÍVEIS: <numero_nivel> <palavra_nivel>
<numero_nivel> <palavra_nivel>]
O comando NIVEIS define os níveis de segurança em termos de privacidade. O OpenBASE possibilita a atribuição de níveis de leitura e gravação, para cada item de dados. Cada nível de privacidade é definido associando-se um número de nível com sua respectiva palavra de nível. Os números de níveis são representados por inteiros de 1 a 15 e devem ser especificados em ordem crescente na codificação do Esquema do Banco de Dados. As palavras de níveis são constituídas por ate 6 caracteres, sendo o primeiro caractere obrigatoriamente uma letra. A declaração dos níveis é opcional. Caso seja declarado algum nível, e necessário declarar também o nível máximo, ou seja, associar uma palavra de nível ao nível 15.
Exemplo:
NIVEL: 01 todos
05 superv
10 gerent
12 diret
15 dba
Após declarar o Banco e seus atributos, dentro do esquema, pode ser feita a declaração dos arquivos, tabelas ou relações de cada Banco de Dados conforme a seguinte Sintaxe
[RELACOES:]
NOME: [<percurso>] <nome_arquivo> <tipo_arquivo>...
[ESQUEMA = [<percurso_orig>] <nome_orig>...
<seg_origem>...
[<nivel_origem>] ]
[REGISTRO:]
<nome_item> [{[<rep>] / (<ligações>) / (<caminho>)/(0)}]...
<tipo>:<tamanho>[,<num_decimais>] ... | |
[(<num_nivel_ler>,<num_nivel_grav>)] ...
[{POS <nome_item_rd>[+ <deslocamento>] /...
VIRTUAL (<nome_item_part>, ..., <nome_item_part>)}] ...
[UNICA]
...
...
A seguir descrevemos os comandos utilizados na declaração dos arquivos de dados em Bancos de Dados OpenBASE assim como as suas respectivas opções. Veja o manual específico do sistema DEFINE para maiores detalhes.
|
Comandos |
Explicação |
|
RELAÇÕES: |
Para documentar o início das declarações dos arquivos de dados de um Banco, utiliza-se, opcionalmente, a declaração RELAÇÕES: |
|
NOME: |
Marca o início da declaração de cada arquivo de dados |
|
<percurso> |
Especifica o percurso onde será criado o arquivo de dados. Em caso de omissão, será assumido o mesmo percurso utilizado para o Dicionário de Dados |
|
<nome_arquivo> |
Especifica o nome do arquivo de dados e consiste de uma cadeia com até 10 caracteres com as seguintes restrições:
No MS-DOS, <nome_arquivo> não pode ultrapassar 8 caracteres |
|
<tipo_arquivo> |
Especifica o tipo do arquivo de dados, designado por uma letra. Tipos Básicos: E e R Referências Externas aos tipos básicos: T e C Tipos documentacionais: A, L e F Observações Arquivos do tipo Tabela se referem a arquivos do tipo Entidade pertencentes a outros Banco de Dados e arquivos do tipo Consulta, se referem a arquivos Relacionamentos pertencentes a outros Banco de Dados. Arquivos tipo T ou C, também podem participar de Subesquemas. A definição de um arquivo tipo T ou C deve contemplar todos os itens chaves do arquivo que esta sendo referenciado (E ou R). Os tipos dos arquivos documentacionais são convertidos pelo DEFINE para os tipos básicos. Assim sendo, Entidade Associativa ou Entidade de Ligação e convertida para Entidade, assim como, Entidade Fraca e convertida para Relacionamento |
|
ESQUEMA = |
Esta cláusula só será utilizada no caso de interseção de Banco de Dados, ou seja, se o tipo do arquivo for T (tabela) ou C (consulta). Em função de um arquivo tipo T ou C se referir a um arquivo de um outro Banco de Dados, esta clausula determina que na compilação do Esquema ou Subesquema, seja aberto o Banco de Dados, ao qual o arquivo tipo T ou C se refere (BDR), com a finalidade de consistir as estruturas de ambos os arquivos, ou seja, o que se refere com o que está sendo referenciado. Assim sendo, todos os itens declarados no arquivo tipo T ou C devem existir no arquivo tipo E ou R que está sendo referenciado no BDR e em conseqüência os tipos e tamanhos dos itens devem ser idênticos |
|
<percurso_orig> |
Percurso onde se encontra o Dicionário de Dados do Banco de Dados ao qual o arquivo pertence efetivamente |
|
<nome_orig> |
Nome do Dicionário de Dados do Banco de Dados ao qual o arquivo pertence efetivamente |
|
<seg_origem> |
Código de segurança do Banco de Dados ao qual o arquivo pertence efetivamente |
|
<nivel_origem> |
Palavra de nível do Banco de Dados ao qual o arquivo pertence efetivamente |
Exemplos:
<< BANCO exemplo1 33 ** Banco hipotético ** >>
NOME: arq_dpto E << Entidade Departamentos >>
NOME: arq_func A << Entidade Funcionários>>
<< BANCO exemplo2 44 ** Banco hipotético ** >>
NOME: arq_func T ESQUEMA=exemplo1 33
NOME: arq_proj E << Entidade Projetos >>
NOME: arq_part R << Relacionamento Participação >>
A declaração dos itens de dados e feita logo a seguir a declaração do arquivo de dados cujos itens de dados fazem parte do seu registro. Veja a sintaxe do comando:
[REGISTRO:]
<nome_item> [{[<rep>]/(<ligações>)/(<caminho>)/(0)}]
... <tipo>:<tamanho>[,<num_decimais>]
... [(<num_nivel_ler>,<num_nivel_grav>)]
... [{POS <nome_item_rd>[+<deslocamen>] |
... VIRTUAL (<nome_item_part>, ..., <nome_item_part>)}]
... [UNICA]
A seguir descrevemos os comandos utilizados na declaração de um Banco de Dados OpenBASE assim como as suas respectivas opções. Veja o manual específico do sistema DEFINE para maiores detalhes.
|
Comandos |
Explicação |
|
REGISTRO: |
Opcionalmente, para documentar o inicio das declarações dos itens de dados que compõem o registro de um arquivo de dados, utiliza-se a palavra REGISTRO seguida de dois pontos (:) |
|
<nome_item> |
<nome_item> especifica o nome dos itens que compõem cada registro de um arquivo de dados o qual compõe-se de uma cadeia com até 63 caracteres com as seguintes restrições:
|
|
[<rep>] |
É o fator de repetição de um item. A LDBD não permite que sejam implementados itens multivalorados. Para tanto, o usuário pode definir que um item seja repetido tantas vezes quanto for determinado em <rep>, que consiste de um valor numérico inteiro contido entre colchetes. Este recurso quando utilizado faz com que o DEFINE associe aos nomes dos itens repetitivos, um número seqüencial que varia de 1 a <rep>. Assim sendo, se o nome do item for telefone e o fator de repetição for 3, três itens serão criados com os respectivos nomes: telefone1, telefone2 e telefone3. Observações
|
|
(<ligações>) |
Especifica o número de ligações que a Entidade mantém com outras Entidades, ou seja, e o número de vezes em que a chave primária da Entidade é referenciada como chave estrangeira em outros arquivos do Banco de Dados. Assim sendo, <ligações> é um número que pode variar de 0 a n. Este argumento deve ser declarado somente em arquivos tipo Entidade e ao lado do item que corresponde ao Atributo determinante da Entidade. Desta forma, o item que associa o número de ligações passa a ser a chave primária do arquivo Entidade. Observações
Numa relação entidade (tipo E ou T) o número de ligações pode ser especificado como *, o que será automaticamente substituído pelo número de referências nos arquivos posteriormente definidos, por exemplo: nome: PESSOA e NOMEP (*) u30 << (*) será substituído por (1) >> IDADE n2 nome: FILHOS r NOMEP1 (PESSOA) U30 IDADEF n2 |
|
(<caminho>) |
É o nome do arquivo Entidade com o qual o item de dados ira fazer associação (procedência). Indica que o item e uma chave estrangeira (Atributo Associativo / Item Associativo). Este argumento define de forma declarada o Relacionamento entre as Entidades e assim sendo, determina para o OpenBASE a obrigatoriedade do controle da Integridade Referencial. Observações
|
|
(0) |
Indica que o item é uma chave alternativa, porém se esta chave for a primeira de um arquivo tipo Entidade, define que a Entidade não possui ligações mas assume o papel de chave primária. Caso contrário corresponde a uma chave alternativa que pode ser declarada tanto em arquivos tipo Entidade quanto em arquivos tipo relacionamento. Observações
|
|
<tipo>:<tamanho> |
Define o tipo e o tamanho do Item, assim como o número de casas decimais no caso do item suportar valores numéricos. Tipo do Item O tipo do item a ser declarado em <tipo> poderá ser especificado como: U Universal N Numérico sem sinal S Numérico com sinal P Numérico compactado sem sinal C Numérico compactado com sinal I Numérico Binário (positivo) B Numérico Binário (positivo/negativo) F Numérico Ponto Flutuante (positivo ou negativo) D,D2,D4 Data L Lógico M Multimídia (Objeto Binário Longo) No OpenBASE um item de dado do tipo D2, só aceita datas compreendidas entre 01/01/1901 e 04/06/2080, inclusive, na conversão de uma variável de memória para o item D2 do banco. Caso a data esteja fora deste intervalo, é emitida a mensagem "OPUS(varite) => Estouro na conversão numérica". Para datas com tipo D4 esta conversão pode ser feita para datas dentro ou fora do intervalo mencionado anteriormente. O item D4 indica uma data no formato aaaa/mm/dd onde aaaa ocupa 2 bytes, mm 1 byte e dd 1 byte. O dia 1 é considerado 01/01/0001. A data 31/12/1900 ainda é considerada como data nula para se manter compatibilidade com o tipo D2. Para sua utilização na OPUS em conjunto com as datas tipo D2 foram feitas as seguintes alterações: |
|
<tamanho> |
O tamanho do item a ser declarado em <tamanho>, consiste de um valor numérico que varia em função do tipo do item. Este tamanho nem sempre representa o número de bytes para armazenar o conteúdo do item |
|
<num_decimais> |
Se o item suportar valores numéricos é possuir casas decimais, o número de casas decimais é informado em <num_decimais>, que consiste de um valor numérico entre 1 a 18. Neste caso, o separador entre o tamanho do item e as casas decimais é obrigatoriamente a vírgula (,). As casas decimais são virtuais, assim sendo, internamente, o valor contido em <tamanho>, corresponde ao conteúdo do item com suas respectivas casas decimais: internamente não apresenta separador entre a parte inteira e as casas decimais |
|
(<num_nivel_ler>, |
Especifica um par de números inteiros que declaram o nível de privacidade para leitura e gravação do item de dados. <num_nivel_ler> é o número do nível de leitura que consiste de um número de nível declarado anteriormente em nível, tem que ser menor ou igual ao nível de gravação. <num_nivel_grav> é o número do nível de gravação que consiste de um número de nível declarado anteriormente em nível, tem que ser maior ou igual ao nível de leitura. Os níveis de leitura e gravação estão associados às suas respectivas palavras de níveis e funcionam da maneira seguinte: Na abertura do Banco de Dados, o usuário declara a sua palavra de nível e o OpenBASE converte esta palavra para o número do nível associado à palavra (Numero de Nível do usuário - NNU). Desse modo, permite consistir se o usuário tem ou não autorização para ler ou gravar (atualizar) o item. Assim sendo, se NNU for maior ou igual ao nível de leitura do item, o usuário pode ler o item. Se NNU for maior ou igual ao nível de gravação, o usuário pode gravar o item. Caso o usuário, num procedimento de leitura não seja autorizado a acessar o item, o valor de retorno do item é mascarado em função do seu tipo |
|
POS <nome_item_rd> |
Define que o item é uma redefinição de um outro item de dados, permitindo assim que um item seja decomposto em subitens ou que um item seja composto por itens contíguos. A implementação da redefinição de um item baseia-se na superposição de itens na mesma área de registro. Assim sendo, um item que redefine um outro, não ocupa espaço adicional no registro, em função de utilizar a mesma área de registro ocupada por um ou mais itens já declarados. <nome_item_rd> É o nome do item a ser redefinido que consiste do nome de um item já existente (não pode ser o nome de um item repetitivo). <deslocamento> É o deslocamento em bytes, em relação à posição inicial do item a ser definido que consiste de um número inteiro. Se <nome_item> iniciar na mesma posição de registro, ocupada por <nome_item_rd>, não é necessário informar o <deslocamento> |
|
VIRTUAL (<nome_item_part>, ..., <nome_item_part>) |
Define que o item é um item virtual. A implementação de itens virtuais, baseia-se na montagem em memória da composição de itens. Assim sendo, itens virtuais não ocupam espaço adicional no registro. <nome_item_part>, ..., <nome_item_part>) É a lista dos nomes dos itens que compõem o item virtual. Observações sobre itens virtuais: |
|
ÚNICA |
Estabelece restrição de unicidade para chave secundária (chave única). Não pode ser declarado em chaves primárias devido ao fato deste tipo de chave ser única por definição |
A função OPUS "DTOC", para itens do tipo D2, retorna uma cadeia de caracteres no formato dd/mm/aa se foi especificado set century off e 1901 <= ano <= 1999. Caso contrário, a função retorna uma cadeia no formato dd/mm/aaaa. Para itens do tipo D4, retorna uma cadeia no formato dd/mm/aaaa, mesmo para datas menores do que 1901 e datas maiores do que 1999. A função "CTOD" considera uma cadeia no formato dd/mm/aa como dd/mm/19aa.
Quanto à conversão de variáveis para itens do banco, observe o seguinte:
Se tipo D2, 01/01/1901 <= data <= 04/06/2080, caso contrário é emitida a mensagem OPUS (varite) => Estouro na conversão numérica.
Quanto à conversão do tipo do item D2 para D4 observe o seguinte:
Os itens tipo D2 de um banco de dados podem ser descarregados e carregados no mesmo banco de dados com os itens alterados de tipo D2 para tipo D4.
Para melhor compreensão do <tamanho> do item, consulte a Tabela a seguir.
|
Tipo |
Tamanho |
Tamanho |
Valores Suportados |
Tipo Interno |
|
U |
1 a 2048 |
1 a 2048 |
Cadeia de caracteres |
Cadeia |
|
N |
1 a 18 |
1 a 18 |
Numérico de 1 a 18 dígitos |
Cadeia |
|
S |
1 a 18 |
1 a 18 |
Numérico de 1 a 18 dígitos mais sinal |
Cadeia |
|
P |
2 a 18 (par) |
1 a 9 |
Numérico de 1 a 18 dígitos |
Compactado |
|
C |
1 a 17 (impar) |
1 a 9 |
Numérico de 1 a 18 dígitos mais sinal |
Compactado |
|
I |
2 ou 4 |
2 ou 4 |
Numérico entre 0 e 2 |
Binário |
|
F |
4 a 8 |
4 a 8 |
Numérico de n dígitos. Se tb=4 então n=7 senão n=15. |
Ponto flutuante |
|
B |
1 ou 7 |
1 ou 7 |
Numérico entre 2(8*tb-1) e 2(8*tb-1)-1. |
Binário |
|
D |
2 |
2 |
Data no formato dd/mm/aa entre |
Binário |
|
D2 |
Data no formato dd/mm/aaaa entre |
Binário |
||
|
D4 |
Binário |
|||
|
L |
1 |
1 |
0 -> falso - 1 -> verdadeiro |
Binário |
|
M |
4 |
1 a 4 Gb |
String de Bits |
Binário |
O valor de retorno do item é mascarado em função do seu tipo, conforme tabela abaixo.
|
Tipo dos itens |
Máscaras |
|
U |
Espaços em branco |
|
N,S,P,C,I,B.F |
Cadeia de dígitos preenchida com o número nove (999999999) |
|
D,D2,D4 |
Data em branco ("//") |
|
L |
Falso (zero) |
Exemplos:
NOME: arq_dpto E << Entidade Departamento >>
<< Declaração dos itens da Entidade Departamento >>
sigl_dpto (1) u2
nome_dpto u30
NOME: arq_func E << Entidade Funcionário >>
<< Declaração dos itens da Entidade Funcionários >>
matr_func (1) u5
nome_func u30
data_nasc u6
dian u2 POS data_nasc
mesn u2 POS data_nasc + 2 <<ou POS dian + 2 >>
anon u2 POS data_nasc + 4 <<ou POS mesn +2 >>
sexo_func(0) u1
salario [12] B4,2 (5,10)
cpf_func (0) u11 UNICA
chave_aux(0) u4 VIRTUAL (anon, mesn)
NOME: arq_lota R << Relacionamento Lotação >>
<< Declaração dos itens do Relacionamento Lotação >>
dpto_lota (arq_dpto) u2
func_lota (arq_func) u5
data_lota d2
O comando DEFINE aciona o compilador de Esquemas e Subesquemas que darão origem efetivamente à criação do Banco de Dados conforme a seguinte Sintaxe
DEFINE [-<opcao>] <nome_Esquema>, onde:
A seguir descrevemos o comando DEFINE assim como as suas respectivas opções. Veja o manual específico do sistema DEFINE para maiores detalhes.
|
parâmetros |
Explicação do parâmetro |
|
-a <nome arquivo> |
transfere a listagem do Esquema para o arquivo de <nome arquivo> |
|
-c <nome arquivo> |
informa o nome de um arquivo que contém os nomes dos arquivos do Banco de Dados que deverão ser recriados, mesmo se existirem |
|
-e |
permite a execução do "DEFINE" em background |
|
-f |
suprime a listagem do Esquema |
|
-p <nome do programa> |
O "DEFINE" cria um "pipe" para o programa <nome do programa> |
|
-I |
direciona a listagem do Esquema para o SPOOL |
|
<nome_Esquema> |
é o nome do arquivo fonte que contém o Esquema ou Subesquema a ser compilado |
|
-s |
Indica que não será perguntado ao usuário, se deseja recriar os arquivos do banco de dados. Substitui a opção $controle SEMARQUIVO, utilizada no esquema do banco de dados |
Os ambientes OpenBASE oferecem uma grande variedade de facilidades para auxiliar os usuários na execução das tarefas administrativas inerentes aos Bancos de Dados.
Esse conjunto integrado de recursos OpenBASE recebe o nome de Sistema de Utilitários de Bancos de Dados (SUBD) apresentando programas voltados para a manutenção e administração de Banco de Dados, permitindo, por exemplo:
Este capítulo focaliza os utilitários, principalmente do ponto de vista das plataformas UNIX, cujos nomes são precedidos do prefixo BD (Banco de Dados). Na versão Windows, os nomes dos utilitários OpenBASE são prefixados por WIN em vez de BD.
Não é recomendável que os usuários acessem Bancos de Dados OpenBASE utilizando outros meios diferentes das interfaces e utilitários oferecidos pelo OpenBASE, pois estes garantem a consistência e integridade das informações. As maneiras de invocar os utilitários OpenBASE são:
A seguir apresentamos uma lista dos utilitários OpenBASE e suas respectivas funções globais.
Para obter maiores detalhes consulte os manuais específicos na .
Utilitário Descrição global
BDADIC Adiciona registros a arquivos de Bancos de Dados.
BDCDBF Converte arquivos dbf para a estrutura dos Bancos OpenBASE.
BDCNFG Muda configuração de ambiente.
BDDELE Elimina Bancos de Dados OpenBASE.
BDDESC Descarrega Banco de Dados OpenBASE.
BDESPA Lista relatórios estatísticos dos arquivos de Bancos de Dados.
BDINDC Otimiza a criação de arquivos de índice.
BDINDV Cria uma chave virtual e seu arquivo de índice.
BDLICE Lista tabela de usuários e bloqueios.
BDCODI Lista informações sobre a cópia OpenBASE instalada
BDLIDI Lista transações do diário.
BDMENS Lista mensagens de erro do ambiente OpenBASE.
BDOTIM Otimiza arquivos de índice.
BDRECA Recarrega Bancos de Dados.
BDRECU Recupera Bancos de Dados.
BDREDI Refaz ou desfaz transações em Banco de Dados.
BDRMCE Elimina pontos de controle (semáforos) em situações de contingência.
BDSERV Servidor de Bancos de Dados OpenBASE.
BDSGBD Gerenciador de bloqueios de Bancos de Dados OpenBASE.
BDTETE Lista tabela TERMINFO.
BDVERI Verifica integridade dos Banco de Dados.
BDVESQ Recupera o esquema de um Banco de Dados a partir do seu dicionário.
BDVESCLI Recupera (recria) o esquema de um Banco de Dados Distribuído.
BDSREP Implementa servidores de replicação de Bancos de Dados OpenBASE.
BDCREP Implementa clientes de replicação de Bancos de Dados OpenBASE.
BDSQL OPENBASE Cria esquema SQL a partir do dicionário de Bancos de Dados OpenBase.
OPENB Apresenta em menus os serviços do ambiente OpenBASE.
Para obter maiores detalhes destes utilitários assim como as informações referentes a todos os utilitários consulte os manuais específicos ("Utilitários do OpenBASE") na página internet do OpenBASE.
Neste capítulo será apresentada a relação das sub-rotinas básicas dos produtos OpenBASE que permitem acessar Bancos de dados OpenBASE a partir de quaisquer linguagens de alto nível. A seguir apresentamos uma lista contendo algumas dessas sub-rotinas e a descrição global:
Sub-routina Descrição global
BDABRE abre Banco de Dados
BDACHC acessa primeiro registro para leitura em cadeia
BDACHP acessa primeiro registro para leitura por prefixo
BDALTE altera itens não chave
BDBLOQ bloqueia banco de dados
BDDESB desbloqueia banco de dados
BDDESF desfaz transação corrente
BDESCH seleciona chave de ordem para leitura seqüencial
BDESVA esvazia arquivo
BDEXCL remove registros de arquivos
BDFECH fecha arquivo do banco de dados
BDINCL inclui registros
BDINCA inclui registros no meio de uma cadeia
BDJUNT faz junção no banco de dados
BDPEGC faz leitura em cadeia
BDPEGD faz leitura direta
BDPEGI faz leitura seqüencial invertida
BDPEGM faz leitura por chave
BDPEGP faz leitura por prefixo
BDPEGS faz leitura seqüencial
BDPEGT faz leitura invertida em cadeia
BDPEGV faz leitura invertida por prefixo
BDPOSI posiciona em registro para leitura seqüencial
BDREST restaura a tabela de execução de um arquivo
BDSALV salva tabela de execução de um arquivo
BDTROC altera valores de itens que não são chaves primárias
Para obter maiores detalhes destas rotinas assim como as informações referentes a todos os utilitários consulte os manuais específicos ("Utilitários do OpenBASE") na página internet do OpenBASE.
O ambiente OpenBASE disponibiliza um sistema Interativo de Consulta e Atualização de Bancos de Dados chamado GERAL (Gerador de Aplicações on-line), o qual oferece uma interface interativa e amigável para consultas e atualizações em Bancos de Dados. Adicionalmente, o sistema GERAL oferece os seguintes recursos: apresentação de menus e opções, gerador de relatórios, execução de consultas e atualizações em modo interativo e batch.
Em resumo, o sistema GERAL oferece os seguintes recursos:
Para invocar o GERAL, via terminal, digita-se:
Geral [<arquivo>]
O GERAL responde com:
COMANDO ?
Neste momento, o usuário pode entrar com os comandos. As entradas para o GERAL podem conter qualquer numero de linhas, até 700 caracteres. Em caso de necessidade, o GERAL abre um prompt com o sinal de interrogação na primeira coluna da linha seguinte ao comando digitado. Todas as entradas de comandos ou dados para o GERAL, são terminados com a tecla {ENTER}.
O GERAL permite que o usuário trabalhe na modalidade Batch, ou seja, os comandos para o GERAL podem ser especificados dentro de um arquivo fonte, criado com um editor de textos.
Neste caso, o GERAL será invocado com o comando:
GERAL <nome-do-arquivo>
Onde: <nome-do-arquivo> é o nome do arquivo com os comandos do GERAL.
Por exemplo:
GERAL commands.p
O arquivo de comandos do GERAL deve conter apenas comandos válidos, um em cada linha. Caso contrário, será enviada mensagem de erro e a execução será cancelada.
A seguir apresentamos uma lista dos comandos do sistema GERAL com uma descrição geral:
comando
descrição globalACEITE Invoca processador de telas ou retornar para a tela que invocou um processo
ALTERE Substituir valores dos itens de um arquivo.
BANCO Informar ao GERAL o Banco de Dados que será utilizado.
CALCULE Calcular novos valores para itens numéricos no arquivo de seleção.
DESLIGUE Desligar opções do GERAL.
ENTRE Atribuir valor digitado pelo usuário a uma variável de memória.
EXCLUA Remover registros de um arquivo do banco de dados.
EXECUTE Executar um programa externo ao GERAL.
EXIBA Exibir texto no dispositivo de saída.
EXPLIQUE Exibir explicações sobre os comandos do GERAL.
GERCLI Conectar um servidor de Banco de Dados.
IMPRIMA Imprimir relatório formatado no dispositivo lógico associado.
INCLUA Acrescentar registros em um arquivo do banco de dados.
INFORME Exibir a estrutura do banco de dados utilizado.
LIGUE Ligar opções do GERAL.
LISTE Listar registros selecionados.
PROCEDA Executar arquivos com comandos do GERAL.
SAIA Terminar a execução do GERAL, retornando o controle ao sistema operacional.
SELECAO Armazenar o endereço dos registros selecionados em arquivo para uso posterior.
SELECIONE Selecionar registros de um arquivo do banco de dados.
UNIDADE Trocar o dispositivo lógico para exibição das informações.
Para obter maiores detalhes consulte os manuais específicos na página internet do OpenBASE.
O OpenBASE disponibiliza as funções e rotinas de manipulação de Bancos de Dos para serem utilizadas pelas linguagens Visuais Basic, Delphi ou outras ferramentas RAD, podendo, assim, ser elaborados aplicativos para acessar Bases de Dados OpenBASE utilizando variadas ferramentas de desenvolvimento.
O acesso aos Bancos de Dados OpenBASE pode ser feito através de bibliotecas dinâmicas (DLLs do OpenBASE), através dos recursos ODBC (Driver ODBC do OpenBASE) e utilizando interfaces COM e DCOM para acessar objetos e métodos OpenBASE. Os componentes OpenBASE podem ser disponibilizados para aplicativos desenvolvidos em diversos ambientes de programação, por exemplo:
As ferramentas RAD (Rapid Application Development) possuem, geralmente, as seguintes características:
As funções e objetos OpenBASE estão agrupados em duas bibliotecas de ligação dinâmica (DLLs), conforme a seguir:
|
ROTWIN32.DL |
Biblioteca principal com as rotinas básicas de acesso ao Banco de Dados OpenBASE. |
|
CLIWIN32.DLL |
Similar a biblioteca ROTWIN32.DLL, porém as rotinas são voltadas para aplicações cliente dentro de uma arquitetura CLIENTE/ SERVIDOR em redes TCP-IP. |
O módulo CLIWIN32.DLL inclui as funções para arquitetura cliente/servidor e permite desenvolver aplicativos cliente cujos servidores podem residir em qualquer outra plataforma, local ou remota, conforme veremos nos exemplos apresentados. As funções (ou rotinas) e métodos incluídos nessas bibliotecas dinâmicas permitem acessar e controlar Bancos de Dados OpenBase. Podemos agrupar todas as funções disponíveis em categorias, conforme a seguir:
|
Categoria das funções |
Nome das funções |
|
Leitura Seqüencial |
ReiniciaCadeia LeProximo[Registro]Sequencial Le[Registro]AnteriorSequencial EscolheChave ObtemRegistrosNoArquivo |
|
Leitura por Cadeia |
IniciaCadeia LeProximo[Registro]Cadeia Le[Registro]AnteriorCadeia PosicionaNoRegistroPorChave ObtemRegistrosNaCadeia |
|
Leitura por Prefixo |
IniciaPorPrefixo LeProximo[Registro]PorPrefixo Le[Registro]AnteriorPorPrefixo |
|
Leitura por Chave Primária |
Le[Registro]PorChavePrimaria |
|
Leitura por Endereço |
Le[Registro]PorEndereco PosicionaNoRegistro ObtemEnderecoAtual |
|
Inclusão, Exclusão e Alteração de Registro |
ExcluiRegistro ExcluiRegistroCascata ExcluiRegistroPoeNulo Inclui[Todo]Registro Inclui[Todo]RegistroNaCadeia Altera[Todo]Registro Altera[Todo]RegistroCascata Altera[Todo]RegistroPoeNulo |
|
Conexão e Controle de Bancos |
AbreBancoDeDados FechaBancoDeDados JuntaBancoDeDados IniciaServidor FinalizaServidor |
|
Manipulação de Memos |
PegaGravaItemMemo LePoeItemMemo ExcluiItemMemo ObtemPercursoItemMemo ObtemTamanhoMemo |
|
Itens especiais |
PoeItem PegaItem |
|
Rotinas Genéricas |
Bloqueia Desbloqueia SalvaTabelaExecucao RestauraTabelaExecucao IniciaTransacao FinalizaTransacao DesfazTransacao LigaOpcao DesligaOpcao EsvaziaArquivo Crypt |
|
Rotinas para Obter Informações |
ObtemItensDoArquivo ObtemInfoSobreItem ObtemQtdChaves ObtemChaves ObtemNumeroDoItem ObtemInfoSobreArquivo ObtemQtdLigacoes ObtemLigacoes ObtemNumeroDoArquivo ObtemQtdDeJuncoes ObtemJuncoes ObtemQtdVirtuais ObtemVirtuais ObtemTipoDaChave ObtemQtdItensBasicos ObtemItensBasicos ObtemQtdRedefinicoes ObtemRedefinicoes ObtemNiveis ObtemInfoSobreBanco ObtemInfoSobreCadeia ObtemDiretorio ObtemCliente ObtemMensagem |
Neste manual não apresentamos em detalhe as funções e métodos incluídos nas DLLs nem os exemplos de aplicativos desenvolvidos em ambientes RAD tais como Visual Basic e Delphi.
Para obter maiores detalhes consulte os manuais específicos na página internet do OpenBASE.
O OpenBASE incorporou às linguagens OPUS e OPUSWin algumas ferramentas de programação Internet, Intranet e Extranet, que facilitam o desenvolvimento de aplicativos em servidores WEB. Esses comandos e funções constituem uma extensão das linguagens OPUS e OpusWin e recebem o nome de OpusWEB e estão disponíveis para as seguintes plataformas e ambientes operacionais:
As linguagens OPUS e OPUSWin oferecem recursos para a construção dinâmica de aplicativos Cliente/Servidor em ambientes Internet e Intranet, utilizando as interfaces CGI (Common Gateway Interface) e ISAPI (Internet Server Application Program Interface), padrões amplamente utilizado nos servidores WEB.
Ao desenvolver aplicativos ISAPI ou CGI, é necessário compreender claramente os mecanismos de funcionamento dessas interfaces de programação. Todos os problemas encontrados na utilização da OPUSWEB se relacionam, direta ou indiretamente, com o desconhecimento dos padrões e mecanismos CGI e/ou ISAPI.
Por isso, a compreensão destes assuntos constitui requisito básico para desenvolver scripts, programas, extensões ou filtros para servidores Web.
Abordamos, inicialmente, alguma idéias básicas a respeito dos seguintes assuntos:
Os serviços da plataforma Web estão baseados no modelo cliente/servidor, que permite distribuir e compartilhar os seus componentes básicos, ou seja, a interface com o usuário, a lógica dos programas e os dados. No modelo cliente/servidor, o cliente:
No modelo cliente/servidor, o servidor:
Nos modelos tradicionais, os clientes e os servidores são classificados de "magros" ou "gordos". Estes termos indicam mais uma relação funcional do que características físicas. Trata-se de uma divisão do trabalho ditada pelo perfil do próprio aplicativo. Por exemplo, é bastante freqüente que o servidor seja otimizado para fornecer dados a múltiplos clientes e, usualmente, a aplicação cliente é otimizada para, apenas, interagir com o usuário final.
O servidor é "gordo" quando toda a lógica funcional reside nele. Este é, ainda, o modelo mais comum na Web. O cliente "magro" é, usualmente, um Browser, que fornece apenas a interface com o usuário. Ou seja, as aplicações CGI ou ISAPI fornecem a lógica funcional dentro do servidor HTTP e o cliente apenas exibe os dados. Existem outros modelos cliente / servidor, com serviços distribuídos. Neste caso, as atividades são compartilhadas entre cliente e servidor.
Os clientes Web são também chamados "User agents" ou, simplesmente, Browsers. No passado, por serem os Browsers meras interfaces com o usuário, o modelo era "servidor gordo, cliente magro". Contudo, atualmente, existem tecnologias (por exemplo, Applets, Client-side Scripts, Style Sheets, plug-ins ...) que permitem maior grau de programação e processamento do lado do cliente.
A expressão cliente, ou "User Agent" se refere, usualmente, ao parceiro de uma sessão HTTP que inicia o pedido ("request") a ser atendido ("response") pelo servidor Web.
Na medida que a grande rede mundial (World Wide Web) cresce, em recursos e complexidade, novos tipos de "User Agents" são inventados para prover novas funcionalidades junto aos usuários.
Servidores Web são processos que aceitam conexões (ou seja, sessões HTTP) solicitadas por clientes Web (Browsers) e, em resposta, fornecem informações na forma de mensagens e documentos de variados tipos, por exemplo, textos, imagens, som, vídeo ... etc ...
O desenvolvimento de servidores Web começou em 1990 e, atualmente, existem centenas de milhares de servidores Web na Internet, além de um número desconhecido de servidores utilizados nas Intranets corporativas.
Inicialmente, e durante algum tempo, apenas havia opções de servidores Web para plataformas UNIX. Atualmente, existem bons Servidores Web para plataformas Win32 e Mac.
Os servidores Web utilizam o protocolo HTTP (Hypertext Transfer Protocol) que foi implementado para permitir uma transferência rápida e eficiente de documentos na Internet".
Consulte o manual específico da para obter maiores detalhes e aprender a programar OpusWEB.
HTTP é um protocolo fácil de entender, pois é baseado no paradigma pedido e resposta (request e response). Uma transação HTTP, independente da sua complexidade, possui a seguinte estrutura elementar:
O protocolo HTTP é "stateless" por natureza. Isto quer dizer que cada transação (pedido e resposta) é completada de forma independente, não sendo preservadas as informações de status referentes às transações anteriormente completadas. Isto exige um nível maior de controle e complexidade na programação de aplicativos Web.
Existem vários métodos e recursos que permitem administrar essa complexidade das transações HTTP.
Consulte o para maiores detalhes.
A Linguagem Estruturada de Consulta (SQL) baseia-se num ambiente chamado SQL OPENBASE (Tecnocoop SQL), o qual implementa todos os recursos disponíveis da SQL ANSI sob o OpenBASE.
A linguagem do SQL OPENBASE é totalmente compatível com a SQL padrão ANSI X3.135 - 1986, com as seguintes extensões apresentadas pelo ISO ANSI working draft (jan/1988): criação e eliminação dinâmica de Tabelas, Visões, Índices e Privilégios, Comandos dinâmicos SQL, Comando LOCK TABLE, Dados do tipo DATA, Integridade Referencial, SQL embutida na linguagem OPUS, SQL embutida na Linguagem C, dentre outras.
Outros aspectos importantes da SQL OPENBASE:
Para obter maiores detalhes consulte os manuais específicos na página internet do OpenBASE.
O OpenBASE possui linguagens de programação de alto nível. A linguagem OPUS permite desenvolver aplicativos para plataformas UNIX e WIN32 utilizando a interface caractere ou Console Application. No que diz respeito à manipulação de Bancos de Dados, a OPUS oferece ferramentas, comandos e funções poderosos e de grande performance pois está plenamente integrada ao ambiente e estrutura do OpenBASE. Além disso, a linguagem OPUS permite acessar qualquer tipo de Banco de Dados utilizando o ODBC e conjugando, desta forma, os recursos da SQL.
Um programa escrito em OPUS, quando submetido ao processo de pre-compilação, é traduzido para linguagem C/C++, para então ser efetivamente processado pelo compilador C/C++. Isto quer dizer que todo programa escrito na linguagem OPUS precisa de um compilador C/C++ para tornar-se uma função, uma procedure, um programa executável. Consulte o para maiores detalhes.
Um programa escrito em OpusWin, quando submetido ao processo de pre-compilação, é traduzido para linguagem C/C++, para então ser efetivamente processado pelo compilador C/C++. Isto quer dizer que todo programa escrito na linguagem OPUS precisa de um compilador C/C++ para tornar-se uma função, uma procedure, um programa executável (.EXE) ou uma DLL (.DLL). Veja como construir DLLs utilizando a OpusWin consultando o .
O processo de gerar programas C/C++ oferece total portabilidade e alta performance às aplicações, além de permitir que o usuário possa agregar ao programa (no mesmo fonte e sem restrições), comandos da linguagem C/C++.
A OPUS é uma linguagem de alto nível que permite desenvolver aplicativos em múltiplas plataformas e arquiteturas.
Para obter maiores detalhes consulte os manuais específicos na página internet do OpenBASE.
Os programas escritos na linguagem OpusWin são compatíveis com os programas desenvolvidos na tradicional OPUS, do OpenBASE e aderem plenamente aos padrões WIN32, possuindo, em conseqüência, todas as suas características e vantagens.
Para obter maiores detalhes consulte os manuais específicos na página internet do OpenBASE.
A Visual Opus é uma ferramenta projetada para desenvolvimento de sistemas, implementando os recursos e facilidades das plataformas Windows 9X/NT/2000/XP e visando maior produtividade para usuários dos produtos OpenBASE.
A Visual Opus não é uma linguagem de programação e sim uma interface gráfica que permite a elaboração e/ou modificação de programas OpusWin, utilizando recursos visuais padrão, de forma interativa. A linguagem de programação utilizada pela Visual Opus é a OpusWin, assim como, por exemplo, as linguagens utilizadas pelos ambientes Delphi e Visual Basic são, respectivamente, o Pascal e o Basic.
Os módulos (programas e procedures) produzidos ou manipulados através da utilização da ferramenta Visual Opus podem ser incorporados ao ambiente de produtos da família OpenBASE. Desta forma, a Visual Opus constitui, sem dúvida, um poderoso recurso a ser utilizado no processo de desenvolvimento de aplicações. Os objetivos básicos da Visual Opus são os seguintes:
Para obter maiores detalhes consulte os manuais específicos na página internet do OpenBASE.
O OpenIDE oferece um ambiente integrado de desenvolvimento de aplicativos. Neste tópico apresentamos a estrutura e os conceitos básicos deste recurso OpenBASE.
Uma aplicação desenvolvida nas linguagem OPUS ou OpusWin resulta sempre em um programa principal e, normalmente, em um conjunto de rotinas ou funções. Os programas encontram-se inc;uídos em arquivos segundo critérios definidos pelos autores do projeto de um determinado sistema aplicativo.
O arquivo que contem o programa principal é chamado de arquivo principal e, geralmente, contém também as rotinas e funções utilizadas pelo programa principal. Os demais arquivos, se existirem, contém as rotinas e funções.
O código fonte das rotinas e funções especifica, através da opção $LIBRARY, as bibliotecas onde elas serão armazenadas depois de compiladas e ligadas. O programa principal, por outro lado, deve especificar quais as bibliotecas (opção $LIBRARY) que contém as rotinas e funções utilizadas.
As linguagens OPUS e OpusWin possuem a facilidade de incluir, dentro de um programa, função ou rotina, trechos de código contidos em arquivos chamados de inclusão (INCLUDE).
A compilação dos modolos fonte que compõem uma aplicação deve ser feita na seguinte ordem:
Como conseqüência:
O ambiente integrado OpenIDE é constituído por três janelas:
O tamanho destas janelas pode ser alterado a qualquer momento utilizando o mouse, clicando e arrastando as barras de separação ou utilizando os botões apresentados na barra de ferramentas.
Os elementos de um determinado sistema aplicativo são agrupados em projetos, contituídos por:
Para criar novos projetos basta acionar o menu Arquivos/Criar Projeto. O OpenIDE mostrará uma caixa de dialogo onde deverá ser informado o nome completo (incluído o percurso) do projeto a ser criado. Isto feito, uma nova caixa de dialogo será exibida permitindo a especificação dos arquivos que farão parte do projeto. Se nada for informado o projeto será criado vazio, isto é, sem arquivos.
Para abrir um projeto existente basta acionar o menu Projeto/Abrir Projeto. O OpenIDE mostrará uma caixa de dialogo onde será informado o projeto que está sendo aberto.
Assim que o projeto for criado ou aberto ele será mostrado na árvore da janela projeto.
Os elementos que compõem um determinado projeto OpenIDE são agrupados, organizados e apresentados utilizando árvores com a seguinte estrutura hierárquica:
Ao lado de cada item da árvore pode existir um pequeno quadrado contendo o símbolo mais (+) ou o símbolo menos(-). A sua inexistência informa que o item não possui subitens. Se estiver preenchido com (+), significa que existem subitens, porém não estão sendo mostrados. Para exibi-los basta clicar no pequeno quadrado. Se existir preenchido com (-),significa que existem subitens e estão mostrados. Para que os subitens deixem de ser vistos, basta clicar no pequeno quadrado.
A construção de um projeto é iniciada pelo menu Projeto/Construir. Construir ium projeto significa executar, na ordem correta, todas as compilações e ligações que se fizerem necessárias como conseqüência das modificações feitas nos arquivos após a ultima construção realizada. O arquivo principal é compilado se todos os arquivos de rotina foram corretamente compilados. O resultado da compilação do arquivo principal é um arquivo executável ou DLL.
O processo de construção pode ser acompanhado pelas mensagens mostradas na janela de mensagens. No caso de erros de compilação de um arquivo, um duplo clique na linha que o informa fará com que o arquivo seja colocado na janela de texto com a linha do erro selecionada.
A construção de um projeto pode ser interrompida pelo comando de menu Projeto/Interromper Construção. A construção será interrompida ao final da compilação que estiver sendo executada.
Os projetos OpenIDE podem ser modificados a qualquer momento, podendo-se incluir ou remover os elementos que o compõem.
Através do menu Projeto/Reconstruir todo um poderá ser reconstruído sendo recompilados todos os seus programas, rotinas e funções.
Para inserir arquivos no projeto basta comandar o menu Projeto/Inserir ou utilizar a tecla Insert com a janela do projeto selecionada. A resposta a este comando é a exibição de uma caixa de dialogo aonde os arquivos a serem inseridos poderão ser selecionados. Para remover arquivos de um projeto basta seleciona-los na árvore e teclar a tecla Delete ou acionar o menu Projeto/Remover.
Para exibir um arquivo do projeto basta dar um duplo clique em seu nome na arvore do projeto. O conteúdo desse arquivo será mostrado na janela texto.
Na janela ComboBox acionada através da barra de ferramentas estão todas as rotinas e funções pertencentes ao projeto. Selecione a região de edição da ComboBox, digite a inicial do nome da rotina a ser vista. Uma janela ListBox será aberta mostrando todas as rotinas ou funções cujos nomes iniciam com a letra inicial escolhida. Clique na rotina que deseja visualizar e o arquivo que a contém será colocado na janela texto.
O comando de menu Projeto/Executar dispara, se necessário, a construção do projeto e em seguida se a construção foi bem sucedida comanda a execução do .exe gerado.
Para compilar um determinado módulo fonte de um projeto:
Os erros de compilação serão mostrados na janela de mensagens e um duplo clique na linha que o informa fará com que a linha do erro apareça selecionada na janela texto, aonde poderá ser feita a correção.
Embelezar um arquivo é reformatá-lo utilizando uma indentação que realça os loops, os case etc... permitindo que a leitura do programa seja facilitada. Para embelezar um determinado arquivo, faça o seguinte:
A função de verificação do projeto, acionada através do menu Projeto/Verificação, analisa os componentes do projeta para detectar:
Todos os problemas detectados são informados na janela de mensagens. Um duplo clique na linha da de uma mensagem fará com que o arquivo nela citado seja visualizado na janela texto. Se a mensagem referencia uma rotina ou função, a linha que contém a rotina será selecionada.
O Opendba é uma ferramenta de Administração de Dados cujo objetivo é auxiliar o DBA na execução de trabalhos de criação e manutenção de banco de dados. Você pode:
Existem três maneiras de operação no Opendba:
Para ativar o modo de operação selecione no menu: Arquivo/Preferências.
 A tela do Opendba é dividida da seguinte maneira:
A tela do Opendba é dividida da seguinte maneira:
Onde:
Todas as funções do Opendba aplicam-se no item que está selecionado na árvore.
Você pode criar um banco Openbase se uma das opções do menu mostradas abaixo estiverem selecionadas:
a) Arquivo/Preferências/Mostrar só Esquemas ou
b) Arquivo/Preferências/Mostrar SQL e Esquemas
Primeiramente você precisa de um esquema para compilar. Neste esquema estão definidos os atributos do banco, as tabelas e os itens que pertencem às mesmas.
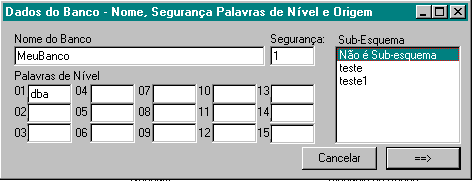
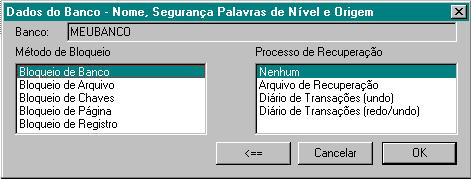
Mantenha o esquema selecionado na árvore, e ative no menu Esquema/Inserir Arquivo em ..., ou aperte a tecla INS . Aparece o diálogo para criação de arquivos.

Leia as instruções com atenção. Depois de clicar na seta, digite o nome do arquivo e selecione o tipo. Para encerrar clique no botão OK. Repita este passo para cada arquivo que quiser inserir no banco de dados.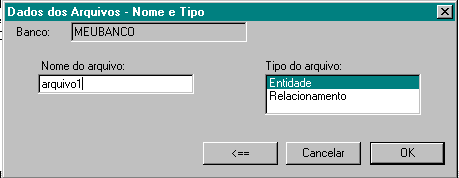
Depois que o arquivo foi criado é hora de inserir campos. Na árvore, posicione-se sobre um arquivo. No menu, selecione Esquema/Inserir Campo em... ou aperte a tecla INS como atalho. Repare que surge na árvore a mensagem Item sendo definido. No diálogo para criação de campos, digite o nome do item e a espécie e clique no botão com a seta para direita.
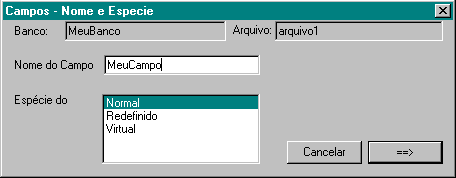
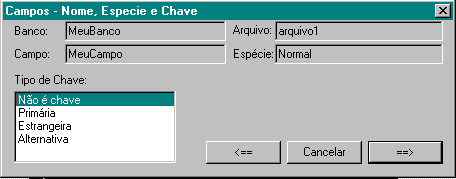 Depois, selecione o tipo da chave,
Depois, selecione o tipo da chave,
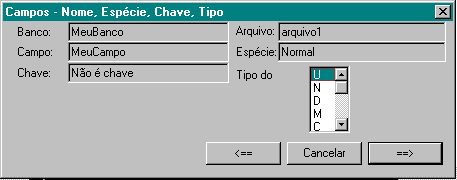 selecione o tipo do item
selecione o tipo do item
e vá para a próxima caixa de diálogo.

Digite o tamanho do campo, o tipo de segurança e o número de repetições. Clique OK para adicionar o item ao esquema. Repita para cada item que for inserido no arquivo.
Para compilar o esquema criado, selecione:
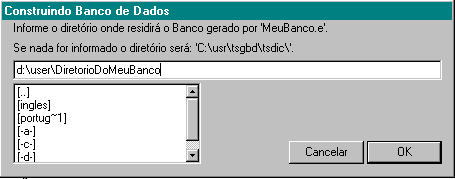 Na caixa de diálogo selecione o diretório onde ficará o banco e clique OK.
Na caixa de diálogo selecione o diretório onde ficará o banco e clique OK.
Selecione na árvore, na seção Metadata/Bancos de Dados o banco que será removido. Depois selecione no menu:
Você também pode usar a tecla DEL como atalho.
Primeiramente, uma das opções abaixo deve estar selecionada:
Se Arquivo/Preferências/Mostrar SQL e Esquemas estiver selecionado:
Para remover um esquema selecione na árvore o esquema que você quer remover, e no menu, selecione Esquema/Remover Esquema... ou aperte a tecla DEL.
Para remover um arquivo, selecione na árvore o arquivo que voçê quer remover, e no menu, clique em Esquema/Remover Arquivo... ou aperte a tecla DEL.
Para remover um campo, selecione na árvore o campo que voçê quer remover, e no menu, clique em Esquema/Remover Campo....
Se Arquivo/Mostrar só Esquemas estiver selecionado: Selecione na árvore o objeto Openbase que quer remover e clique em Esquema/Remover Objeto para cada um deles.
Primeiramente, a opção Arquivo/ Preferências/Mostrar SQL e Esquemas deve estar selecionada. Depois selecione na árvore em Metadata/Bancos de Dados, o banco que vai ser preparado. Selecionado o banco, ative no menu a opção Banco/Integrar Catálogo SQL. Leia o texto que está na dialog box e caso queira, modifique o caminho onde será gerado o catálogo SQL. O diretório default para criação da base SQL é c:\usr\tsgbd\tsdic\db. O diretório db é o diretório de localização dos arquivos que contém informações sobre a base SQL que está sendo criada. Quando você selecionar o diretório, por exemplo, c:\teste, você deve acrescentar mais um, por exemplo, c:\teste\base1ou c:\test\db ou qualquer nome que queira. Este procedimento é obrigatório, caso contrário aparecerá a mensagem Diretório já 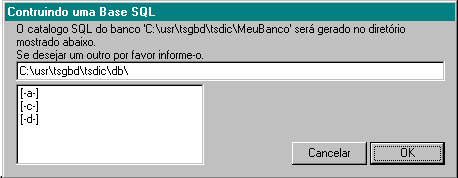 existe.
existe.
Primeiramente, a opção Arquivo/Preferências/Mostrar SQL e Esquemas deve estar selecionada.Selecione na árvore, no caminho Metadata/Bancos de Dados um banco que tenha associado a ele o ícone (H). Este ícone indica que o banco esta com o acesso SQL disponível. Depois, selecione no menu Banco/Remover Catálogo SQL, << Falta terminar >>.
Para criar um banco de dados SQL umas das duas opções do menu abaixo precisam estar selecionadas:
Selecione no menu Banco/Cria Base SQL, que ativará a caixa de diálogo abaixo:

Primeiramente é necessário que no menu uma das duas opções abaixo estejam selecionadas:
Selecione na árvore, no caminho Metadata/Bancos de Dados SQL o banco SQL que quer remover. Depois, selecione no menu Banco/Remove Base SQL ou simplesmente aperte a tecla DEL. Responda SIM a confirmação.
Primeiramente é necessário que no menu uma das duas opções abaixo estejam selecionadas:
Depois, selecione na árvore o banco de dados SQL que quer usar, no caminho Metadata/Bancos de Dados SQL.
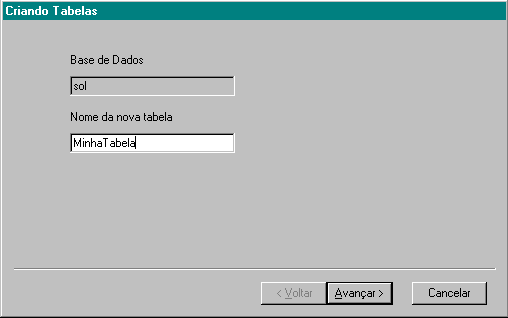
No menu, selecione Banco/Inserir Objeto Sql/Tabelas e a primeira caixa de dialogo aparece:
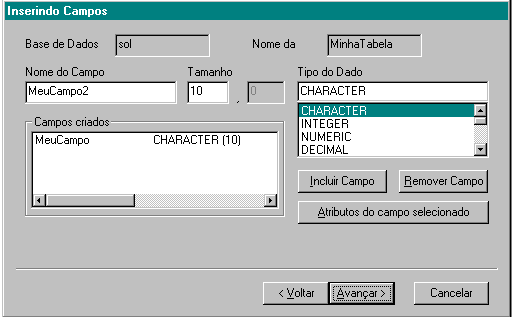
Para verificar os atributos de um campo, selecione na lista Campos Criados , e clique no botão Atributos do campo selecionado . Alguns atributos também podem ser definidos nesta caixa.
Para remover um campo , selecione na lista Campos Criados e clique no botão
Remover Campo. Clique em Avançar para continuar.
Para criar uma chave primária , dê um duplo clique na lista Campos Criados , em cada campo que pertença a chave. Para remover algum campo da chave, basta posicionar o ponto de inserção na caixa Campos que compõem a chave primária e remova com a tecla DEL.. Clique em Avançar para continuar.
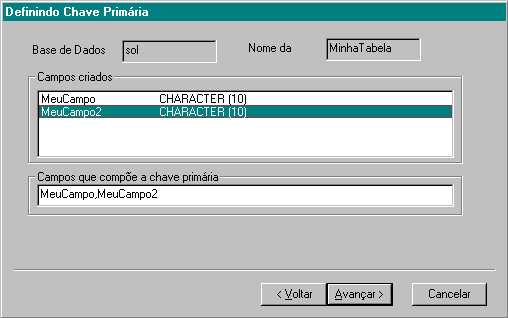
Note que ao criar a primeira chave, o botão Ver Todas é ativado. Este botão permite que você veja todas as chaves que foram criadas.

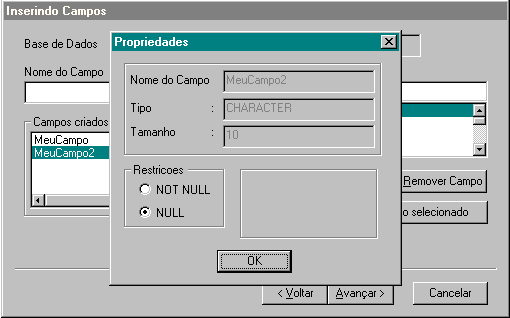
Com um duplo clique sobre um campo na lista Campos Criados os atributos do campo selecionado são mostradas numa caixa de propriedades.
Para remover uma chave, selecione uma chave na lista Chaves Criadas e clique no botão Deletar. A chave é marcada para ser deletada. Para confirmar clique no botão OK. Para sair do diálogo sem modificações, clique em Cancelar.
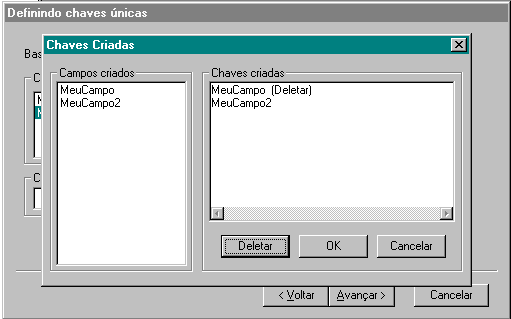 Para continuar, clique em Avançar.
Para continuar, clique em Avançar.
5) Para criar chaves estrangeiras selecione o campo na lista Campos Criados e selecione qual a tabela que será a referencia para este campo na lista Tabelas Existentes. A lista de tabelas existentes só será preenchida com tabelas do banco que tenham chaves definidas, senão a lista estará vazia, porque só é possível fazer referência a chaves existentes.
Escolha o tipo de UPDATE e DELETE e clique em Avançar.
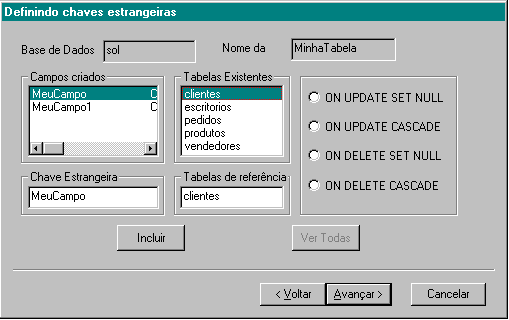
Por fim, entra o último diálogo, que mostra o comando CREATE TABLE que dará origem a nova tabela. O comando CREATE SCHEMA é usado para identificar que as linhas seguintes serão comandos SQL.
Primeiramente é necessário que no menu uma das duas opções abaixo estejam selecionadas:
Depois, selecione na árvore o banco de dados SQL que quer usar, no caminho Metadata/Bancos de Dados SQL. Depois, selecione a tabela que quer remover.
No menu, selecione Banco/Remover Objeto SQL/Tabelas. Confirme a operação.
Primeiramente é necessário que no menu uma das duas opções abaixo estejam selecionadas:
Depois, selecione na árvore o banco de dados SQL que quer usar, no caminho Metadata/Bancos de Dados SQL. No menu, selecione Banco/Inserir Objeto Sql/Visões e uma caixa de dialogo aparece:

Na caixa de texto já vem escrito um template para o comando.
Substitua <Coloque aqui o nome da visão> pelo nome da visão que vc quer criar.
Substitua <Coloque aqui o comando SELECT> pelo comando de seleção de registros.
Exemplo: Criando uma visão chamada Visao1 que conterá todos os registros do arquivo pedidos, do banco sol.

Note que depois que a visão foi criada, ela automaticamente é incluida na árvore, no caminho do banco do qual ela se originou.
Primeiramente é necessário que no menu uma das duas opções abaixo estejam selecionadas:
Depois, selecione na árvore o banco de dados SQL que quer usar, no caminho Metadata/Bancos de Dados SQL. Depois, selecione a visão que quer remover.
No menu, selecione Banco/Remover Objeto SQL/Visões. Confirme a operação
Um esquema SQL é um arquivo texto contendo comandos SQL. O texto deve ser obrigatóriamente iniciado pelo comando CREATE SCHEMA, indicando que as linhas a seguir conterão comandos SQL. Para que o esquema seja executado, um arquivo de esquema deve estar aberto, ou o esquema deve estar digitado na janela de texto.
Primeiramente é necessário que no menu uma das duas opções abaixo estejam selecionadas:
Depois, selecione na árvore o banco de dados SQL que quer usar, no caminho Metadata/Bancos de Dados SQL. No menu, selecione Banco/Executar Script.
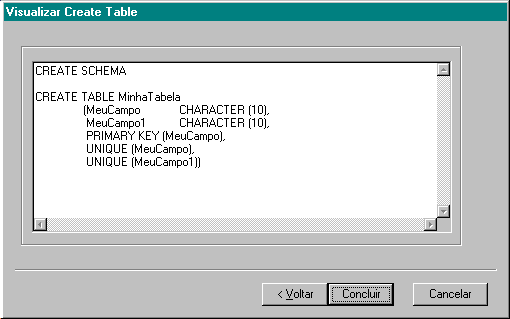
Abre-se um diálogo de abertura de arquivo. Por default, os arquivos que contém esquemas SQL tem extensão .esq, mas pode se usar qualquer extensão. Escolha o arquivo selecionando-o e clicando OK. Se o arquivo já estiver aberto, isto é, está na janela de edição, clique em Cancelar. Depois da operação acima, clique OK ou Cancelar, para confirmar ou abortar a execução.Abaixo, vemos um pequeno exemplo de arquivo de esquema:
CREATE SCHEMA
CREATE TABLE MinhaTabela
(MeuCampo CHARACTER (10),
MeuCampo1 CHARACTER (10),
PRIMARY KEY (MeuCampo),
UNIQUE (MeuCampo),
UNIQUE (MeuCampo1))
Às vezes um banco pode ficar bloqueado por várias razões, como falta de luz, processos bloqueados por um programa mal-comportado, etc. Para resolver este problema, selecione na árvore o banco que você quer recuperar e:
Se você tiver selecionado Arquivo/Preferências/Mostrar SQL e Esquemas, clique no menu na opção Utilitários/Específicos para SQL/Recuperar Banco SQL.
Se você selecionou Arquivo/Preferências/Mostrar só SQL, clique no menu na opção Utilitários/Recuperar Banco SQL.
Para que seja possível refazer ou desfazer transações num banco de dados SQL OPENBASE a opção para criação do jornal deve ter sido ativada quando da criação do banco SQL. Esta opção não deve ser usada quando da criação de acesso SQL para bancos de dados Openbase.
Existem duas maneiras de se ativar a função, dependendo do modo de trabalho selecionado: Arquivo/Preferências/Mostrar SQL e Esquemas:
Selecione na árvore, abaixo de Bancos de Dados SQL o banco de dados que deve ter as transações modificadas. Então, clique no menu em Utilitários/Específicos para SQL/Transações.
Arquivo/Preferências/Mostrar só SQL
Selecione na árvore, abaixo de Bancos de Dados SQL o banco de dados que deve ter as transações modificadas. Então, clique no menu em Utilitários/Transações.
No diálogo que é mostrado abaixo, é necessário que algumas informações sejam preenchidas:
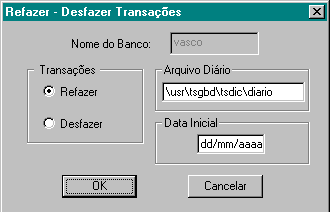
O nome do arquivo diário tem como default \usr\tsgbd\tsdic\diario, troque o nome do arquivo se necessário. Se for preciso que se comece de uma data específica, digite a data inicial. Se ficar preenchida com o default dd/mm/aaaa todas as operações gravadas no arquivo diário serão refeitas ou desfeitas a partir data em o arquivo diário começou ser gravado.